Before diving into this tutorial, make sure you’ve gone through the Getting Started with Python Pandas: Installation and Setup guide to install and set up Pandas on your system.
Working with Comma Separated Values (CSV) files is a common task in data analysis, and Python Pandas simplifies this process. In this article, we’ll discuss how to read csv file in python pandas and how to write csv file in python using pandas. By the end of this tutorial, you’ll be able to python pandas read csv file and manipulate it as a DataFrame with ease.
Reading CSV Files with Pandas
Pandas offers a simple function, read_csv(), to read csv file in python pandas. The basic syntax for python pandas read csv is as follows:
import pandas as pd
data = pd.read_csv("file_path.csv")By executing the above code, you can read a CSV file and store its contents in a DataFrame. The file_path.csv is the path to your CSV file.
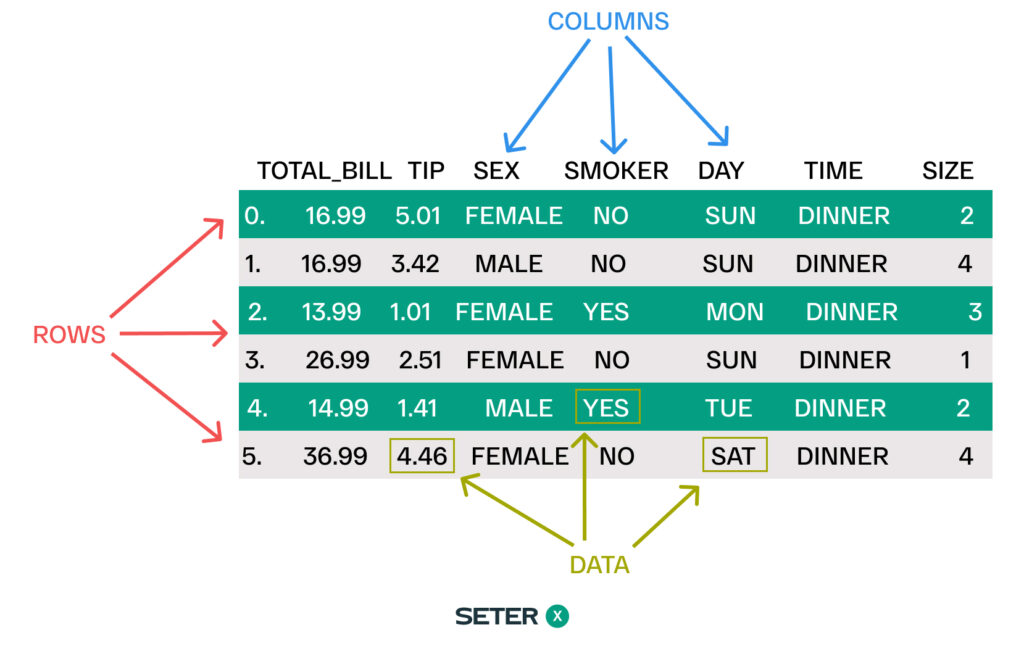
For example, let’s consider the following CSV file named tips.csv:
total_bill,tip,sex,smoker,day,time,size 16.99,1.01,Female,No,Sun,Dinner,2 10.34,1.66,Male,No,Sun,Dinner,3 21.01,3.5,Male,No,Sun,Dinner,3 23.68,3.31,Male,No,Sun,Dinner,2
To read this CSV file and store it as a DataFrame, use the following code:
import pandas as pd
data = pd.read_csv("tips.csv")
print(data)The output will be:
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Customizing CSV Import Options
The read_csv function offers various parameters to customize the import process. Some common parameters include:
sep: Specify the delimiter used in the CSV file (default is,).header: Indicate the row number(s) to use as the column names (default is0, meaning the first row).index_col: Specify the column(s) to set as the index or row labels of the DataFrame.skiprows: Skip a specified number of rows while reading the CSV file.nrows: Read only a specified number of rows from the CSV file.na_values: Specify additional strings to recognize as NaN values.encoding: Specify the character encoding of the CSV file.comment: Specify a character that marks the beginning of a comment in the CSV file. Any lines that begin with this character will be ignored by Pandas when reading the file.
Specify Separator
Let’s consider a CSV file named custom.csv with the following content:
Name|Age|Gender Alice|25|F # This is a comment Bob|30|M Carol|35|F
To read this CSV file with a custom delimiter, ignoring the commented row, you can use the following code:
import pandas as pd
data = pd.read_csv("custom.csv", sep="|", comment="#")
print(data)The output will be:
Name Age Gender 0 Alice 25 F 1 Bob 30 M 2 Carol 35 F
Select Columns
Often, you might only be interested in specific columns of a CSV file. To select only certain columns, use the usecols parameter:
data = pd.read_csv("tips.csv", usecols=["total_bill", "tip"]) total_bill tip
0 16.99 1.01
1 10.34 1.66
2 21.01 3.50
3 23.68 3.31
4 24.59 3.61
.. ... ...
239 29.03 5.92
240 27.18 2.00
241 22.67 2.00
242 17.82 1.75
243 18.78 3.00Skip Columns and Rows
Pandas allow you to skip rows while reading a CSV file using the skiprows parameter. This is useful if you want to ignore header rows or any other rows that aren’t relevant for your analysis.
# Skipping the first row (header row)
data = pd.read_csv("tips.csv", skiprows=[1]) total_bill tip sex smoker day time size
0 10.34 1.66 Male No Sun Dinner 3
1 21.01 3.50 Male No Sun Dinner 3
2 23.68 3.31 Male No Sun Dinner 2
3 24.59 3.61 Female No Sun Dinner 4
4 25.29 4.71 Male No Sun Dinner 4
.. ... ... ... ... ... ... ...
238 29.03 5.92 Male No Sat Dinner 3
239 27.18 2.00 Female Yes Sat Dinner 2
240 22.67 2.00 Male Yes Sat Dinner 2
241 17.82 1.75 Male No Sat Dinner 2
242 18.78 3.00 Female No Thur Dinner 2
[243 rows x 7 columns]Skipping multiple rows
data = pd.read_csv("example.csv", skiprows=[1, 3, 5]) total_bill tip sex smoker day time size
0 10.34 1.66 Male No Sun Dinner 3
1 23.68 3.31 Male No Sun Dinner 2
2 25.29 4.71 Male No Sun Dinner 4
3 8.77 2.00 Male No Sun Dinner 2
4 26.88 3.12 Male No Sun Dinner 4
.. ... ... ... ... ... ... ...
236 29.03 5.92 Male No Sat Dinner 3
237 27.18 2.00 Female Yes Sat Dinner 2
238 22.67 2.00 Male Yes Sat Dinner 2
239 17.82 1.75 Male No Sat Dinner 2
240 18.78 3.00 Female No Thur Dinner 2
[241 rows x 7 columns]Specify Data Types
Sometimes, it’s necessary to specify the data types of the columns in a CSV file, especially when Pandas cannot infer the correct data types automatically. To do this, use the dtype parameter:
data = pd.read_csv("tips.csv", dtype={"size": "float64"}) total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2.0
1 10.34 1.66 Male No Sun Dinner 3.0
2 21.01 3.50 Male No Sun Dinner 3.0
3 23.68 3.31 Male No Sun Dinner 2.0
4 24.59 3.61 Female No Sun Dinner 4.0
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3.0
240 27.18 2.00 Female Yes Sat Dinner 2.0
241 22.67 2.00 Male Yes Sat Dinner 2.0
242 17.82 1.75 Male No Sat Dinner 2.0
243 18.78 3.00 Female No Thur Dinner 2.0Encoding Issues
Occasionally, you may encounter encoding issues when reading CSV files containing non-ASCII characters. To handle such issues, use the encoding parameter and specify the appropriate encoding:
data = pd.read_csv("tips.csv", encoding="utf-8")Read CSV as String
In certain situations, you may need to read the entire CSV file as a string, for example, to preprocess the data before converting it into a DataFrame. You can achieve this using the following approach:
with open("example.csv", "r") as file:
csv_string = file.read()Read Multiple CSV Files
When dealing with multiple CSV files, you can read and concatenate them into a single DataFrame using the following technique:
import glob
file_list = glob.glob("path/to/files/*.csv")
data_frames = [pd.read_csv(file) for file in file_list]
combined_data = pd.concat(data_frames)Handling CSV Headers
By default, Pandas assumes that the first row of the CSV file contains the column names. However, this might not always be the case. You can use the header parameter to handle such situations.
No Header Row
If your CSV file doesn’t have a header row, set the header parameter to None. For example, let’s consider a CSV file named no_header.csv with the following content:
Alice,25,F Bob,30,M Carol,35,F
To read this CSV file without a header, use the following code:
import pandas as pd
data = pd.read_csv("no_header.csv", header=None)
print(data)The output will be:
0 1 2 0 Alice 25 F 1 Bob 30 M 2 Carol 35 F
You can also provide custom column names using the names parameter:
import pandas as pd
column_names = ["Name", "Age", "Gender"]
data = pd.read_csv("no_header.csv", header=None, names=column_names)
print(data)The output will be:
Name Age Gender 0 Alice 25 F 1 Bob 30 M 2 Carol 35 F
Writing DataFrames to CSV Files
To write csv file python pandas, you can use the to_csv function. The basic syntax for writing a DataFrame to a CSV file is as follows:
data.to_csv("output_file_path.csv", index=False)The index parameter is set to False to exclude the index column from the output file. If you want to include the index column, set it to True or remove the index parameter.
Example
Let’s create a DataFrame and write it to a CSV file named output.csv:
import pandas as pd
data = pd.DataFrame({
"Name": ["Alice", "Bob", "Carol"],
"Age": [25, 30, 35],
"Gender": ["F", "M", "F"]
})
data.to_csv("output.csv", index=False)The resulting output.csv file will have the following content:
Name,Age,Gender Alice,25,F Bob,30,M Carol,35,F
Loading Large CSV Files
For large CSV files, it’s more efficient to read the data in chunks. You can achieve this by using the chunksize parameter in the read_csv function. The chunksize parameter specifies the number of rows to read at a time.
Example
Let’s read a large CSV file named large.csv in chunks of 1000 rows:
import pandas as pd
chunksize = 1000
chunks = []
for chunk in pd.read_csv("large.csv", chunksize=chunksize):
# Process the chunk (e.g., filter rows, aggregate data, etc.)
chunks.append(chunk)
data = pd.concat(chunks)In this example, we read the CSV file in chunks and process each chunk separately. Finally, we concatenate the chunks into a single DataFrame using the pd.concat function.
Conclusion
In this article, we explored how to read and write CSV files using Python Pandas. We discussed how to customize the import process, handle headers, and efficiently load large CSV files. By following the examples provided, you can now effortlessly read and write CSV files using Pandas for your data analysis tasks. Make sure to refer to the official Pandas documentation for more advanced use cases and additional features available in the library.
By mastering the techniques presented in this tutorial, you’ll be able to:
- Read and write csv file in python using pandas
- Customize CSV import options such as delimiter, header, index, and more
- Handle CSV headers with different configurations
- Load and process large CSV files in chunks for efficient memory usage
- Create DataFrames from CSV files and save DataFrames to CSV files
With this knowledge, you can confidently utilize Python Pandas for your data manipulation and analysis tasks involving CSV files.