In this tutorial, we will delve into the world of Pandas data manipulation. We will cover various techniques, such as sorting, renaming, and merging DataFrames. These techniques are essential for any data analyst or data scientist working with Pandas, as they make it easier to organize and process data.
By the end of this tutorial, you will have a firm grasp of how to sort DataFrames by values and indices, rename columns and indices, and merge, concatenate, and join DataFrames.
Sorting DataFrames
Sorting is a common operation in data analysis, as it helps us understand and explore the data by arranging it in a specific order. In this section, we will discuss how to sort DataFrames by values and indices.
Sorting by Values
To sort a DataFrame by values, we use the sort_values() method. This method takes several arguments, such as the column(s) to sort by, the sorting order (ascending or descending), and whether to sort in place or return a new DataFrame.
Let’s first create a sample DataFrame:
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 28, 23],
'Score': [80, 90, 85, 88, 92]
}
df = pd.DataFrame(data)
print(df)Now, let’s sort the DataFrame by the ‘Score’ column:
sorted_df = df.sort_values(by='Score')
print(sorted_df)The output should be:
Name Auditory Creator Score
2 Seter Mngmt 50000 Hontar 20
3 Seter AI 40000 Vasiukou 40
1 Seter Develop 100000 Hontar 70
0 Seter Design 100000 Vasiukou 90By default, sort_values() sorts in ascending order. To sort in descending order, pass the ascending=False argument:
sorted_df = df.sort_values(by='Score', ascending=False)
print(sorted_df)Here is the output:
Name Auditory Creator Score
0 Seter Design 100000 Vasiukou 90
1 Seter Develop 100000 Hontar 70
3 Seter AI 40000 Vasiukou 40
2 Seter Mngmt 50000 Hontar 20You can also sort by multiple columns by passing a list of column names:
sorted_df = df.sort_values(by=['Auditory', 'Score'], ascending=[True, False])
print(sorted_df)And the output for the following example:
Name Auditory Creator Score
3 Seter AI 40000 Vasiukou 20
2 Seter Mngmt 50000 Hontar 40
0 Seter Design 100000 Vasiukou 90
1 Seter Develop 100000 Hontar 70In the example above, the DataFrame is first sorted by ‘Auditory’ in ascending order, and then by ‘Score’ in descending order.
Sorting by Indices
To sort a DataFrame by its index, use the sort_index() method. This method also accepts the ascending and inplace arguments.
Here’s an example of sorting our DataFrame by index in descending order:
df.sort_index(ascending=False, inplace=True)
print(df)The output should be:
Name Auditory Creator Score
3 Seter AI 40000 Vasiukou 20
2 Seter Mngmt 50000 Hontar 40
1 Seter Develop 100000 Hontar 70
0 Seter Design 100000 Vasiukou 90Renaming Columns and Indices
It’s not uncommon to encounter DataFrames with unclear or undescriptive column and index names. In such cases, renaming them can improve code readability and ease data analysis. In this section, we will discuss how to rename columns and indices in a DataFrame.
To rename columns, use the rename() method with the columns argument. You can pass a dictionary where the keys are the current column names and the values are the new column names. To rename indices, pass a dictionary to the index argument instead.
Here’s an example of renaming the ‘Name’ column to ‘Subniche’ and the ‘Score’ column to ‘Content_Score’:
renamed_df = df.rename(columns={'Name': 'Subniche', 'Score': 'Content_Score'})
print(renamed_df) Subniche Auditory Creator Content_Score
3 Seter AI 40000 Vasiukou 20
2 Seter Mngmt 50000 Hontar 40
1 Seter Develop 100000 Hontar 70
0 Seter Design 100000 Vasiukou 90You can also rename the index labels by passing a dictionary to the index argument:
df.index = pd.Index(['A', 'B', 'C', 'D'])
renamed_df = df.rename(index={'A': 'X', 'B': 'Y'})
print(renamed_df)Name Auditory Creator Score X Seter AI 40000 Vasiukou 20 Y Seter Mngmt 50000 Hontar 40 C Seter Develop 100000 Hontar 70 D Seter Design 100000 Vasiukou 90
By default, the rename() method returns a new DataFrame. If you want to rename columns or indices in place, set the inplace=True argument:
df.rename(columns={'Name': 'Subniche', 'Score': 'Content_Score'}, inplace=True)
print(df)Merging, Concatenating, and Joining DataFrames
Often, you’ll need to combine data from multiple DataFrames to create a new, unified DataFrame. In this section, we will discuss three methods for achieving this: merging, concatenating, and joining DataFrames.
Merging DataFrames
Merging DataFrames is similar to performing a join operation in SQL. The pd.merge() function allows you to merge two DataFrames based on a common column or index.
Consider the following two DataFrames:
df1 = pd.DataFrame({
'ID': [1, 2, 3, 4, 5],
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 28, 23]
})
df2 = pd.DataFrame({
'ID': [1, 2, 3, 4, 5],
'Score': [80, 90, 85, 88, 92],
'Grade': ['B', 'A', 'B+', 'B+', 'A']
})
print(df1)
print(df2)To merge these DataFrames on the ‘ID’ column, we can use the pd.merge() function:
merged_df = pd.merge(df1, df2, on='ID')
print(merged_df)ID Name Age Score Grade 0 1 Alice 25 80 B 1 2 Bob 30 90 A 2 3 Charlie 35 85 B+ 3 4 David 28 88 B+ 4 5 Eve 23 92 A
By default, pd.merge() performs an inner join. However, you can perform left, right, and outer joins by specifying the how argument. For example, to perform a left join, set how='left':
merged_df = pd.merge(df1, df2, on='ID', how='left')
print(merged_df)ID Name Age Score Grade 0 1 Alice 25 80 B 1 2 Bob 30 90 A 2 3 Charlie 35 85 B+ 3 4 David 28 88 B+ 4 5 Eve 23 92 A
Refer to the Pandas documentation for more details on merging DataFrames.
Concatenating DataFrames
Concatenating DataFrames involves stacking them on top of one another (vertically) or side by side (horizontally). The pd.concat() function accepts a list of DataFrames to concatenate.
Let’s create two DataFrames to concatenate:
df1 = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Score': [80, 90, 85]
})
df2 = pd.DataFrame({
'Name': ['David', 'Eve'],
'Age': [28, 23],
'Score': [88, 92]
})
print(df1)
print(df2) Name Age Score
0 Alice 25 80
1 Bob 30 90
2 Charlie 35 85
Name Age Score
0 David 28 88
1 Eve 23 92
To concatenate these DataFrames vertically, pass them as a list to pd.concat():
concatenated_df = pd.concat([df1, df2], ignore_index=True)
print(concatenated_df)Name Age Score 0 Alice 25 80 1 Bob 30 90 2 Charlie 35 85 3 David 28 88 4 Eve 23 92
The ignore_index=True argument resets the index of the resulting DataFrame. If you don’t provide this argument, the original indices will be preserved.
To concatenate DataFrames horizontally, set the axis=1 argument:
df1 = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
})
df2 = pd.DataFrame({
'Score': [80, 90, 85],
'Grade': ['B', 'A', 'B+']
})
concatenated_df = pd.concat([df1, df2], axis=1)
print(concatenated_df)Name Age Score Grade 0 Alice 25 80 B 1 Bob 30 90 A 2 Charlie 35 85 B+
In this example, we concatenated two DataFrames with the same number of rows side by side.
Joining DataFrames
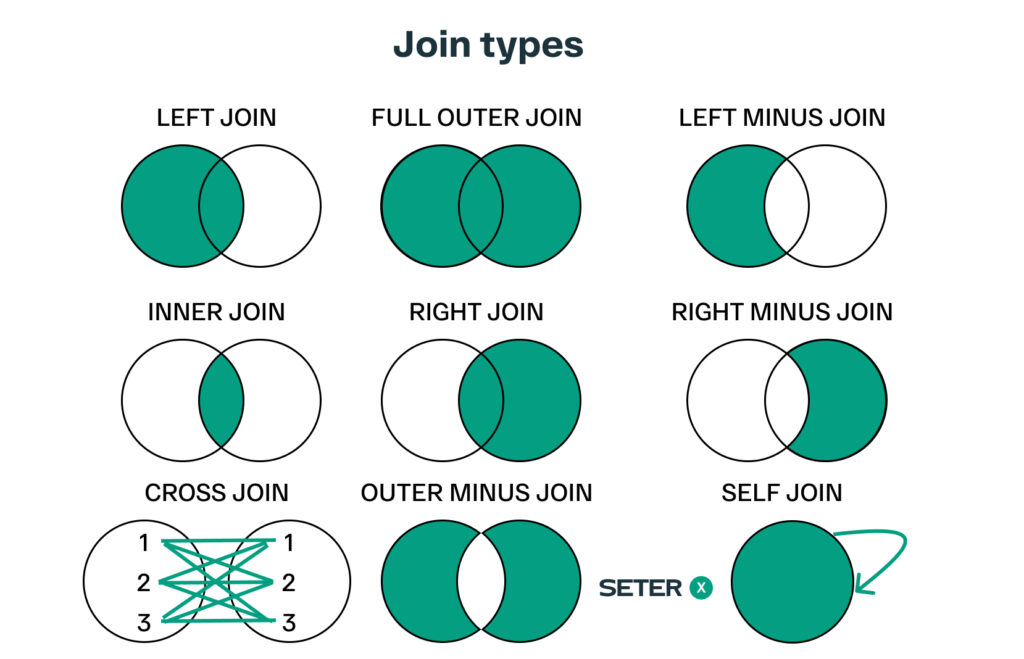
The join() method allows you to join two DataFrames based on their indices. This method is useful when you need to combine DataFrames with different column structures.
Consider the following two DataFrames:
df1 = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 28, 23]
}, index=['A', 'B', 'C', 'D', 'E'])
df2 = pd.DataFrame({
'Score': [80, 90, 85, 88, 92],
'Grade': ['B', 'A', 'B+', 'B+', 'A']
}, index=['A', 'B', 'C', 'D', 'E'])
print(df1)
print(df2)To join these DataFrames on their indices, use the join() method:
joined_df = df1.join(df2)
print(joined_df)Name Age Score Grade A Alice 25 80 B B Bob 30 90 A C Charlie 35 85 B+ D David 28 88 B+ E Eve 23 92 A
By default, the join() method performs a left join. You can perform other types of joins (right, inner, outer) by specifying the how argument.
For example, to perform an outer join, set how='outer':
joined_df = df1.join(df2, how='outer')
print(joined_df)Name Age Score Grade A Alice 25 80 B B Bob 30 90 A C Charlie 35 85 B+ D David 28 88 B+ E Eve 23 92 A
Frequently asked questions
Conclusion
In this tutorial, we explored various Pandas data manipulation techniques, including sorting, renaming, and merging DataFrames. You learned how to sort DataFrames by values and indices, rename columns and indices, and merge, concatenate, and join DataFrames.
Now that you have mastered Pandas data manipulation, you can continue learning about other aspects of Pandas, such as data selection and filtering, grouping and aggregating data, and data visualization.